术业有专攻 (One might be a master in his own field.)
What is domain-driven development (DDD)
DDD was coined by Eric Evans in the book of “Domain-Driven Design: Tackling Complexity in the Heart of Software”, published in 2003. The book gave a clear definition of DDD and how the principle can be used in the modern software design and implementation. In general, DDD asks for focus on the design and development of software components by following the domain-specific characteristics. It requires the domain experts to delineate the problems at the logical level, with which the blueprints of the software design can be put together to map to the business logics. Given the hierarchical or aggregational structures of domain layers in a DDD application, communications of various components for deciding how they can be designed and implemented are important.
The following chart demonstrates a tactical diagram of DDD-based architecture.
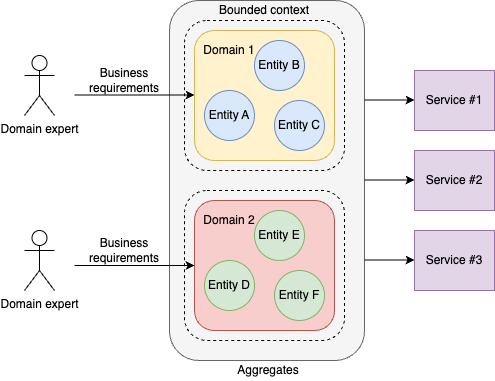
Assuming the entire system is segmented into various sub-domains,
- the strategic design starts from the domain experts who give the business requirements to the implementation.
- Each of the sub-domain is implemented by following the “model” logic given by the domain experts. The model of the domain is usually detailed as bounded context, entities, etc.
- Usually an aggregation happens on top of the domains to connect to the services that are commonly stateless.
The modern data-intensive applications are featured by the complexity of functionalities, data characteristics, front-end user interfaces, etc. Designing and developing data-centric applications for domain-specific use is challenging due to the gap of knowledge in “translating” specifications from the perspectives in one domain to another.
Ubiquitous language
Ubiquitous language plays the core role in DDD. It’s usually hard to synergize a cross-domain ubiquitous language that servers to all purpose. Taking a look at the above diagram, the descriptions of the domain-specific characteristics at different layers should be depicted by using the consistent language. A good ubiquitous language is featured by
- its expressivity of domain-specific traits.
- its universally adaptivity across domains.
- its understandability by people from different domain backgrounds.
- and its clarity in defining technical implementation details.
By definition, domain in DDD refers to a conceptual subject area about how users apply the software. At a coarse granularity, domains can be dichotomized into business domain and technical domain. The ubiquitous language for the inter and inner connections among the technical and business domains should hence be universal and consistent to drive the same conceptual definition and delineation of the domain-specific characteristics.
Business-to-tech (b2t) translation
The biggest challenge usually lies in the translation from the business request to the technical problem. And it can be quite repetitive and iterative. A good translation usually requires practice with the team in understanding the problem precisely - example techniques of event storming, requirement engineering, business process modelling.
The conventional approach
Given the complexity of the data-intensive applications, usually, the requirements of the entire system have to be broken into several components. Consider a scenario where the business in a financial service organization wants to implement a transaction system that tracks the client’s transactions on certain products that the company sells. The business is seeking for a service that can be leveraged to produce insights about the transactions such that the corresponding business plans can be determined.
By following the conventional approach in DDD, a model of the core entities in such system should be defined in the first place. In the modern software, this can be easily achieved by leverage the database technologies. On top of it, the business can then specify the domain-specific logics that retrieve the required information for the analysis. The following is an example of the “translation” that converts the business requirements for retrieving product-related information by using a pre-defined data model - without loss of generality, here the model is assumed to the be simplest that describes the entities of client, product, and transaction in the business domain of interest.
With the predefined model, the business requirement can be translated to
technical implementations. For example, assuming the existence of the attribute
purchase_amount and purchase_date in the transaction_table of a database,
the following statement specified by the business can be rearranged into an SQL
query.
Business:
“I want to have the average purchases of all products between 2022 and 2023.”
Data engineer:
SELECT AVG(purchase_amount) AS average_purchases
FROM transaction_table
WHERE purchase_date BETWEEN '2022-01-01' AND '2023-12-31';
In the same or different sub-domains, at the application layer, the functionalities of the applications (APIs) may be advised by the business, too. Similar to above, the requirements of the API implementations in the software service can be translated from the business requirements and engineered into the form that can be used by the developers. The following example demonstrates the translation from the business requirement to the OpenAPI specification of the RESTful API that implements the functionality.
Business:
“I want a service to allow retrieval of average purchases of all products between the specified starting year and ending year.”
Data scientist:
info:
title: Product Purchase API
version: 1.0.0
description: RESTful API to retrieve the average purchase of a product between starting and ending years.
paths:
/average-purchase:
get:
parameters:
- name: productId
in: query
description: ID of the product for which to retrieve average purchase.
required: true
schema:
type: integer
- name: startYear
in: query
description: Starting year for the average purchase calculation.
required: true
schema:
type: integer
- name: endYear
in: query
description: Ending year for the average purchase calculation.
required: true
schema:
type: integer
responses:
'200':
description: Successful response
content:
application/json:
example:
average_purchase: 250.0
'400':
description: Bad request, invalid parameters
'404':
description: Product not found or no data available for the specified period
'500':
description: Internal server error
The nature of business-to-tech translation is to convert the plain language that describes a business problem into a technical prototype or implementation. Usually a knowledgeable human expert such as program manager, product manager, or product owner severs as the middle-layer to translate such requirements. From the above examples of the two basic software components in a domain-specific application, it can be observed that, although the two components, data query and front-end API, are correlated in the same domain, but they require different process to translate the business-domain descriptions to the technical domain specifications, i.e., data model and OpenAPI specifications. One of the possible solutions is to implement an interface by using a generic programming language with the wrapped object-oriented classes to describe these components that serve at different layers in different domains. However, finding a universal yet effective approach to translation is challenging - the process of involving the business and technical teams for iteratively completing and refining the translation is time-consuming.
Can we leverage the advanced LLM technology?
The large language model (LLM) technologies may help enhance the efficiency and effectiveness, as most of the mapping between human descriptions and technical implementations can be “predicted” by the LLM. The ubiquitous language for b2t can be simply the human language! The requirements (NOTE here the requirements refer to functional ones) can be given by prompts to the LLM via the pre-designed interface. The inputs are prompts that templatize the requirements. The prompts can be designed in a way that they can be adaptively used for different components where business need to raise their needs. For example, the above data queries and model building components can be yielded from LLMs with proper prompt engineering. There are a few good practices to draft the prompts. E.g., meta-prompting helps creates reusable “templates” that generate that actual prompts - this can be useful to scaffold skeleton of domain modules with LLM. In addition, the zero-shot or few-shot examples can be leveraged to enhance the accuracy of the translation. Based on the example provided by the paper, the meta-prompt that suffices business requirements to engineer transaction application can be given as below.
# Input:
{CONTEXT GOES HERE}
# System
You are a product owner that specify the requirements of a transaction
application. Propose five functional requirements such that {TASK DESCRIPTION
GOES HERE}.
# Instructions
− Write the commands in one sentence
− The commands should be short and concise
− Write five independent commands
# Examples
1. {EXAMPLES GO HERE}
# Commands:
1.
To detail the above meta-prompt, the following is constructed.
# Instructions
− I want a data model that implements the client, product, and transaction
with the the specified attributes like below.
- I want a service to allow retrieval of average purchases of all products
between the specified starting year and ending year.
- I want the backend implementation of database queries to achieve the above
front-end API service that retrieve the average product purchases between the
specified starting-year and the ending-year.
Another good start of domain-specific meta-prompt can be found in this blog post, where the domain-specific prompting is detailed.
Most of the LLM models are generic - they have been trained on the massive public data. It’s an art to leverage LLM for producing useful results (prompt engineering). Nevertheless, producing domain-specific results from a pre-trained LLM to translate business requirements to technical implementation may need “customization” of the generic models by techniques like fine-tuning, retrieval augmented generation, mixture of experts, knowledge base. Choosing between tuning, retrieval-based augmentation, etc., depends on the availability of data and use case scenario, which is discussed at large here.
Tech-to-tech (t2t) translation
Within the system there may be cross-domain contextualization as well. For example, assuming that the entire system is designed to support both payment and loan. The two sub-domains of payment and loan may have the similar implementation patterns, but they differ in details. The interconnections between the sub-domains are tech-to-tech (t2t) and usually they are through programmatic interfaces. The main difference between b2t translation and t2t translation is that, the former can be flexible at times and the translation process helps iron out the details to be as close to the facts as possible; the latter needs to be 100% deterministic and precise. Hence, it is convenient to leverage the LLM for b2t translation but it might not be easy to do the same for t2t.
Consider the same system where the modules are designed to serve to “clients”, “product”, and “transaction”. Each of these modules may have its own ETL pipeline, data models, data analytical ability, programming interface, etc., and altogether the sub-modules form the “domain”, of the entire system. Obviously, one domain may have interconnections with the others. If these connections are from a technical perspective, the “t2t” translation is required. In the above example, the tables of product, client, and transaction need to be merged, some analytical models (e.g., forecasting of transaction volume) need to be built, and a serving end needs to be exposed (in the form of API). The “ubiquitous language” that is used for synergizing the domains should be therefore deterministic for precise communications. To achieve, developers proposed data model that formalizes the descriptions of entities or objects in each domain and then build the connections or linkage among them. The graph-like scheme guarantees the universal representation of sub-domain behavior and state-description, as well as the synchronization and coordination among these domains. An advanced idea for the same is data mesh. A data mesh favours DDD by virtue of its architectural design where the domain-specific ownership is defined, and a federated approach to govern the data usage among different domains is applied.
The “ubiquitous language” that bridges the data pipeline to the front-end serving layer can be achieved by standardizing the schema design by using an interchangeable format. For example, as for the RESTful APIs, the Swagger specs of the API endpoints should stick to the entities, objects, etc. of the domains. In terms of implementations, it is worth considering the bidirectional conversion of Swagger standard from/to the data schemas used in the data pipeline. For example, it’s common to see various data representations, data types, and data schemas in different components of an application.
| Stage | Data representation | Framework |
|---|---|---|
| Data warehouse | raw file | data lake |
| ETL | Distributed file (parquet, csv, etc.) system | Spark, Hadoop, etc. |
| Data science | In-memory data objects | (In Python) numpy, pandas, tensorflow, etc. |
| Front-end | JSON, protobuf, Avro, XML |
RESTful API, static site files, etc. |
| System config | YAML, system shell file |
OS |
The domain-specific data may appear in all of the places above. The “ubiquitous language” that can be applied to link all of them is therefore important. It is worth noting that most of the above technical specifications can also be conveniently implemented by leveraging LLM, the copilot-like applications. Whilst it can be quite effective to generate initial code-level implementations but to guarantee the 100% precision human developers are still needed to perform quality assurance. It is very difficult to write effective prompts to generate specs across technical domains with the interchangeable format if it is not impossible, and very likely, the prompts may have to be very sophisticated to guarantee the precision and accuracy.
Final thoughts
Finding the most effective ubiquitous language for enhancing DDD is always a challenge. With the growth of complexity in the modern applications, building an efficient “translation” mechanism that passes requirements, specifications, etc., across domains becomes vital. Whilst the LLM technology seems to help in many ways, it is a learning model that is essentially probabilistic such that it is limited to producing cross-domain delineation that require 100% precision and correctness. As a result, the structural way of data representation to serve the t2t translation is still a must to the system.
Hence, in general, a recommended ubiquitous language-driven workflows that optimize both the efficiency and precision for conducting DDD of a complicated data-centric application can be
| # | Task | Key participants |
|---|---|---|
| 1 | Have the domain experts to serve as a middle-layer to translate the strategic design of the system that corresponds to the business requirements. | LLM, Domain Experts, Program Manager |
| 2 | Iron out the details for model, context, entities, and aggregation behaviors. | LLM, Program Manager, Tech Lead |
| 3 | Iterate the above until the architectural design of the software or application is in a desirable shape. | n/a |
| 4 | Choose one or multiple interchangeable format to describe the detailed specifications finalized in the above steps, which can then be applied across multiple domain-specific components. | Tech Lead |
Finding and applying the ubiquitous language is still a collective efforts of multiple teams but hopefully with the progression of the AI technologies the whole process can be made much simpler than before.
References
- Evans, Eric (August 22, 2003). Domain-Driven Design: Tackling Complexity in the Heart of Software. Boston: Addison-Wesley. ISBN 978-032-112521-7. Retrieved 2012-08-12
- Greg Ball, The Importance of Ubiquitous Language, VMWare Tanzu Developer Center, Jan 2023.
- Felipe de Freitas Batista, Develop the Ubiquitous Language, Domain Driven Design, April 2019.
- Ryan Zheng, Prompt Engineering — MetaPrompting, Sep 2023.