Everything should be made as simple as possible, but not simpler.
The way of doing data science is dramatically imfluenced by the proliferation of cloud computing technology:
Years ago, to experiment a random forest based model, researchers had to configure a computing cluster by hand, which usually means weeks or months of system engineering and cooperations with IT department. Now it has become so simple that in 5 minutes a data scientist can deploy one or multiple powerful computing instances on cloud, where commonly used tools and software are pre-installed. That is handy! It not merely saves the engineering efforts in setting up a working environment that data scientists are comfortable with, but also ecnonomizes the cost of administrating computing resources.
Microsoft Azure Data Science Virtual Machine is such a virtual machine that by and large benefits an elastic use for data science in the following aspects:
- Scalability. There are various options of machine sizes on Azure to scale up or down a DSVM.
- Flexibility. The cutting-edge toolkits and frameworks for big data and deep learning, such as TensorFlow, Spark, etc., are off the shelf on DSVMs for toying up machine learning experiments.
- Cost effectiveness. DSVM is agile such that it does not have to be alive all the time in a data science project. It is charged in a “Pay-as-you-go” scheme, and generates cost only being used.
- Interoperability. More than one data scientists can access to and work on DSVMs provided authrority.
- Reproducibility. Proof-of-concepts and experimentation results can be preserved on cloud, and easily reproduced afterwards.
The following diagram depicts an illustrative resource planning scenario on a heterogeneous set of DSVMs for flight delay prediction.
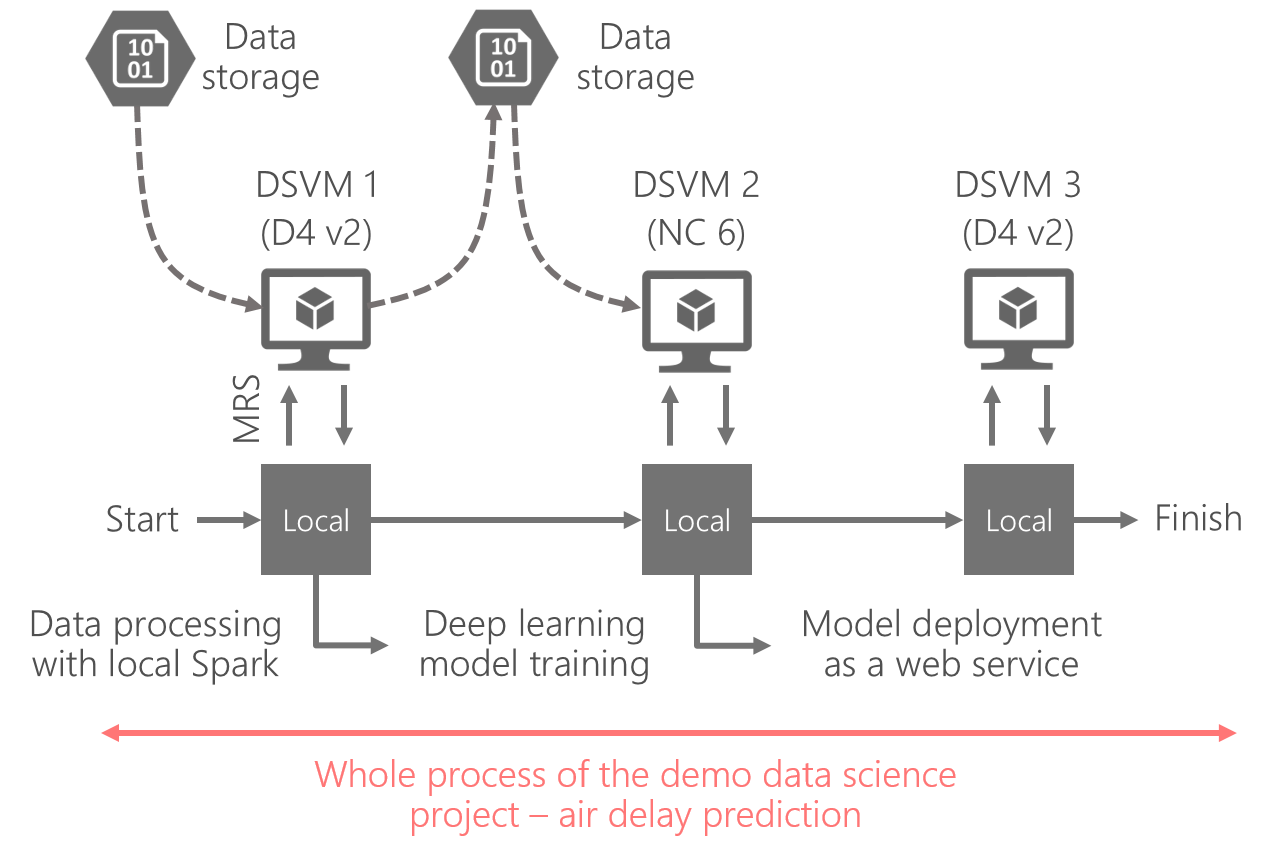 Figure - operationalized DSVMs for flight delay prediction scenario.
The first DSVM is for local standalone Spark based data pre-processing,
the second is for GPU accelerated deep neural network training, and the
third is for model deployment as web services. The three VMs are
featured with different sizes and are priced differently.
Figure - operationalized DSVMs for flight delay prediction scenario.
The first DSVM is for local standalone Spark based data pre-processing,
the second is for GPU accelerated deep neural network training, and the
third is for model deployment as web services. The three VMs are
featured with different sizes and are priced differently.
It is worth mentioning that DSVMs in the piepline can be operationalized programmatically
in R with minimal efforts in manual setup, thanks to Microsoft R
Server and R packages such as
AzureSMR and
AzureDSVM.
Step-by-step tutorial in details can be found at GitHub repository.
Enjoy hacking!