Either you run the day, or the day runs you.
Machine learning vs babysitting
Having been a father for about two months, I found that babysitting can be formalized as an engineering problem which is similar to machine learning. The main task of the babysitting problem is to take care of a baby by fulfiling its needs as much as possible under the constraints that the baby’s life pattern has minimal impact on its parents. The success of babysitting can be quantitatively measured by, for example, the child growth standard proposed by WHO. And the objective is to minimize the deviation between the baby’s data against the standard one.
There are many similarities between babysitting and machine learing.
| Machine learning | Babysitting |
|---|---|
| A model is built. | A baby is taken care of. |
| The model is built by using raw materials (data) generated from various sources. | The baby is raised by using the raw materials (milk) generated from various sources (mommy and the formula milk powder). |
| The raw data need to be featurized before it can be used for model building. | The raw materials need to be featurized, e.g., heated, mixed with water, bottled, etc., before it can be used for baby feeding. |
| The model training process requires parameter tuning to optimize the training objective. | The babysitting process requires parents’ technique tuning to optimize the feeding experience. |
| Regularization is usually applied to avoid overfitting. | Regularization is usually applied to avoid overfeeding. |
| The model is evaluated against the pre-defined quantitaive metrics. | The baby’s growth is evaluated by the pre-defined quantitative metrics, i.e., the WHO child growth standard. |
| The model needs to be repetitively retrained. | The babysitting process needs to be repetitively conducted (feed-play-sleep in every 3 hours a day). |
| Data visualization is vital to building a reliable model. | The baby’s activity visualization is vital to babysitting. |
| It is important yet challenging to explain the model’s behavior. | It is important yet challenging to explain the baby’s behavior. |
| A pipeline with engineering best practices is needed for efficiency enhancement. | A pipeline with the engineering best practices (using the auto formula milk maker machine, the UV sterilizer, etc., applying the 5-min burping technique, etc.) is needed for efficiency enhancement. |
| The pipeline is automated at most but it still requires human involvement. | The pipeline can be automated at most but still it requires A LOT OF human involvement… |
| The model needs to be monitored when it is alive. | The baby needs to be monitored ALL THE TIME regardless whether it is awake or asleep. |
| Sometimes a hot-fix is urgently required to resolve the model issue. | |
| The platforms that are used to host the model should be scalable and flexible. | The crib/clothes/stroller that are used by the baby should be scalable and flexible (the baby grows so fast!) |
System design
Knowing the commonalities between babysitting and machine learning, I am trying to leverage the idea of machine learining system into the design of a babysitting system. To illustrate, a simple system that I am using pragmatically for mine is depicted as below.
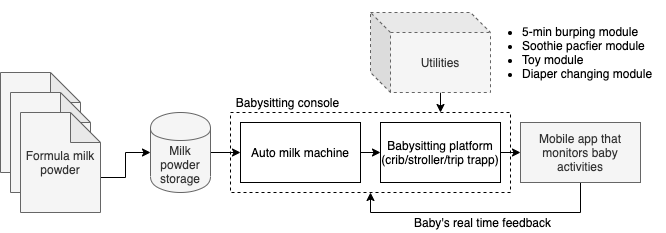
- Considering the use case of formula milk feeding, the pipeline takes the raw input (formula milk powder) to feed the baby, and they are preserved in the storage.
- The core component is the babysitting console where there is an auto milk maker machine to “featurize” the milk powder and a babysitting platform which consists of the crib, the stroller, Stokke Tripp Trap, etc., for the baby to stay in.
- A set of utilities are used to practice the daily babysitting.
- I use a mobile app to collect the real-time data and feedback from baby, with which the decisions are made to fine tune the “parameters” used in the babysitting console.
The system pipeline is run in a batch mode with a frequency of about 3 hours. The front-end feedback is collected in a real-time manner which is used as a supervisory signal. The parameters in the babysitting console and the utilities module are dynamically adjusted to optimize a local objective - reduce the times of cry - and overall, the hollistic system is aimed at making the growth data of the baby as close as the WHO standard.
Gladly, the engineering best practices helps my baby grow with healthiness and happiness - its growth data are slightly above 90% quantile of the WHO child standard for its age. Hopefully with the continuous optimization performed by its parents, the babysitting system will help the baby’s growth in the life-term run with high efficiency!